knative serving 概述
knative serving 概述
1. 前言
KNative是谷歌开源的 serverless 架构方案,旨在提供一套简单易用的 serverless 方案,把 serverless 标准化。目前参与的公司主要是 Google、Pivotal、IBM、Red Hat,2018年7月24日对外发布,目前还处于快速发展的阶段。knative 是为了解决以容器为核心的serverless 应用的构建、部署和运行的问题。
用户只需要编写代码(或者函数),以及配置文件(如何build、运行以及访问等声明式信息),然后运行build和deploy就能把应用自动部署到集群(可以是公有云,也可以是私有云)。其他事情交由serverless平台(比如这里的KNative)自动处理的,这些事情包括:
- 自动完成代码到容器的构建。
- 把应用(或者函数)和特定的事件进行绑定:当事件发生时,自动触发应用(或者函数)。
- 网络的路由和流量控制以及灰度发布
- 函数的自动伸缩
和标准化的 FaaS 不同(只运行特定标准的 Function 代码),KNative 期望能够运行所有的 workload: traditional application、function、container。
knative 建立在 kubernetes 和 istio 平台之上,使用 kubernetes 提供对容器的编排管理能力(deployment、replicaset、和 pods等),以及 istio 提供的网络管理功能(ingress、LB、dynamic route等)。
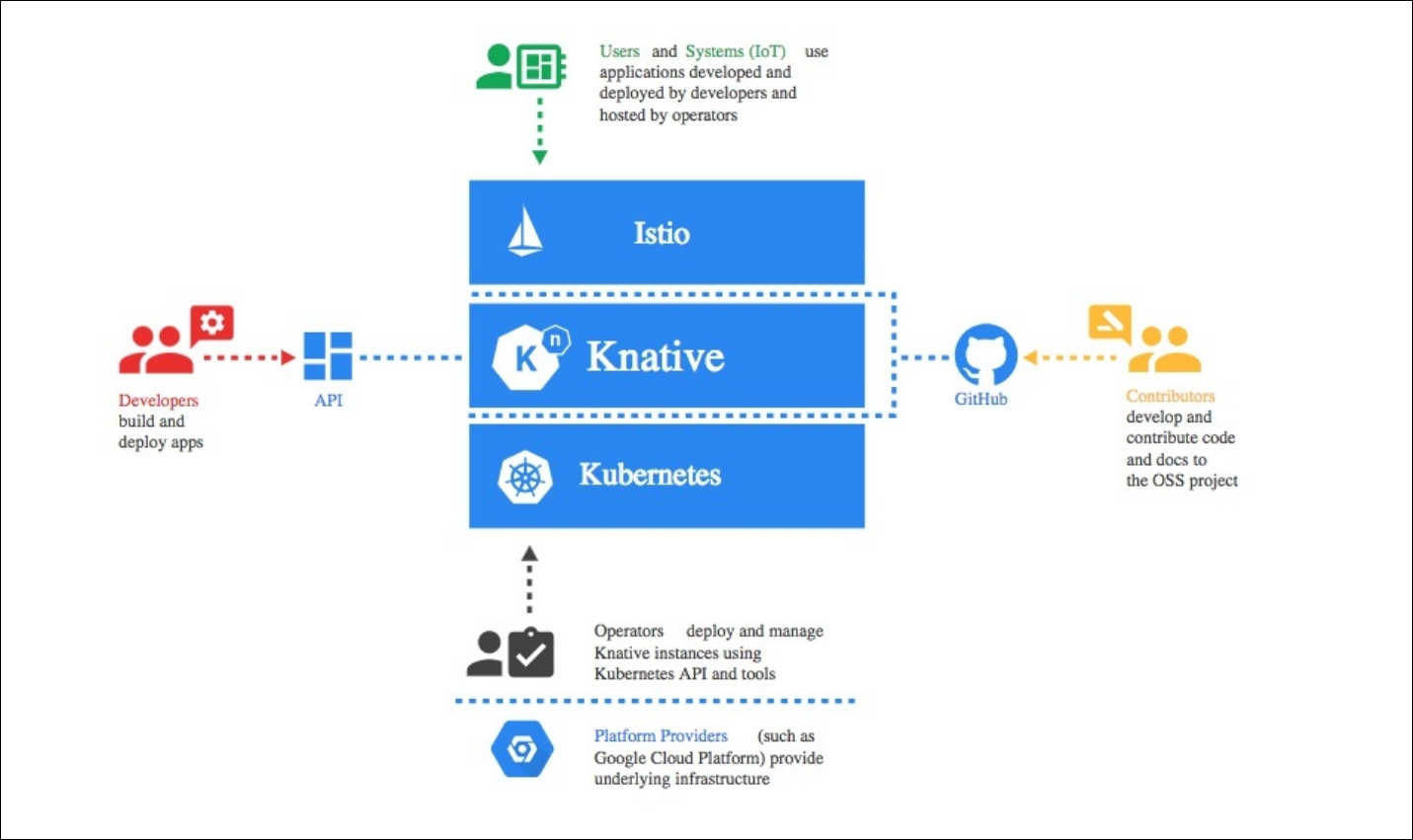
为了实现 serverless 应用的管理,knative 把整个系统分成了三个部分:
- Build:构建系统,把用户定义的函数和应用 build 成容器镜像。
- Serving:服务系统,用来配置应用的路由、升级策略、自动扩缩容等功能。
- Eventing:事件系统,用来自动完成事件的绑定和触发。
本文主要介绍下 knative serving 部分。
2. knative serving 工作原理
knative serving 的核心功能是使用户配置的应用在 kubernetes 中运行起来,并向外提供服务。主要需要实现的功能包括如下:
- 自动化启动和销毁容器
- 根据名字生成网络访问相关的 service、ingress 等对象
- 监控应用的请求,并自动扩缩容
- 支持蓝绿发布、回滚功能,方便应用发布流程
knative serving 功能是基于 kubernetes 和 istio 开发的,它使用 kubernetes 来管理容器(deployment、pod),使用 istio 来管理网络路由(VirtualService、DestinationRule)。而 kubernetes 和 istio 本身的组件和概念非常多,理解和管理起来相对困难,使用起来对用户也不够友好。所以 knative 在此之上基于 k8s CRD 的方式提供了更高一层的抽象,可以如下所示的资源关系图了解 knatvie 工作原理:
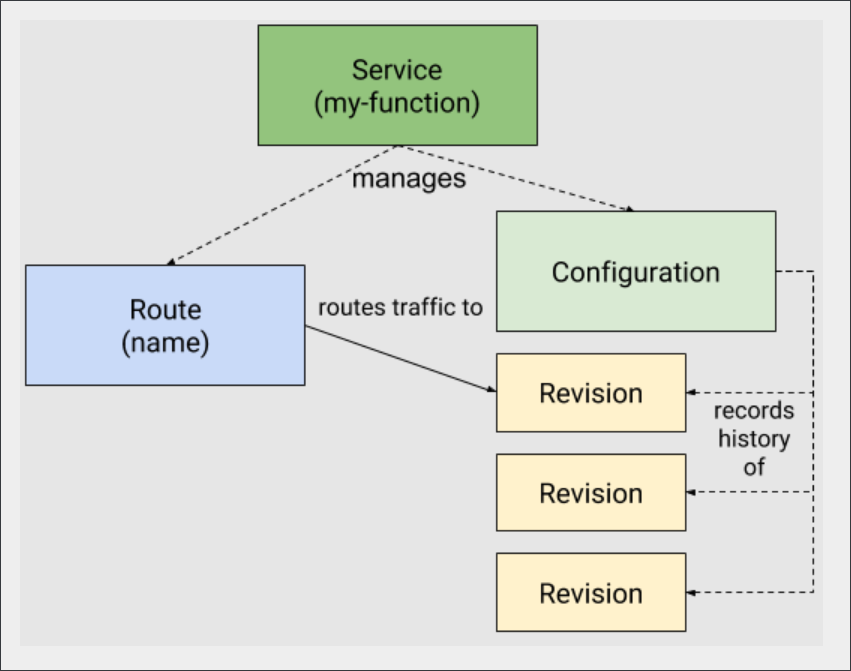
- Service:注意这里 service 不是 kubernetes 中提供服务发现的那个 service,而是 knative 自定义的 CRD,它的全称是 services.serving.knative.dev。单独控制 route 和 configuration 就能实现 serving 的所有功能,但 knative 更推荐使用 Service 来管理,因为它会自动帮你管理 route 和 configuration 中的所有资源。Service 负责管理 workload 的整个生命周期,负责创建相应的 route 和 configuration 资源对象,并通过监听 route、configuration、revision 等资源的变化情况来更新 service 本身。
- Route:knative 定义的 CRD资源,全称是 route.serving.knative.dev。应用的路由规则,也就是进来的流量如何访问应用,对应了 istio的流量管理(VirtualService),route 通过配置多种不同的规则可以实现多版本应用(多个revision)的灰度发布,指定流量分配,动态回滚等功能。
- configuration:knative 定义的 CRD资源,全称是 configuration.serving.knative.dev。应用的最新配置,也就是应用目前期望的状态,维护 kubernetes 的容器的期望数(deployment replicas)。每次应用升级都会更新 configuration,而 knative 也会保留历史版本的记录(图中的 revision),结合 route的流量管理,knative 可以让多个不同的版本共同提供服务,方便蓝绿发布和滚动更新。注意:修改 configuration 将创建新的 revision,而不删除原有的 revision(revision 的删除有 knative gc 来处理)。
- Revision: knative 定义的 CRD资源,全称是 revision.serving.knative.dev。可理解为版本快照,是对工作负荷所做的每个修改的时间点快照。revision 一旦被创建就不会再重新修改(除非删除),每次 configuration 的修改都会对应一个新的revision,每个 revision 都会根据流入的流量自定进行扩缩容操作。
3. knative serving CRD 资源对象
knative 是通过 k8s CRD 的方式建立在 k8s 之上的服务,我们可以根据资源之间的关联关系来做个梳理,如下图所示:
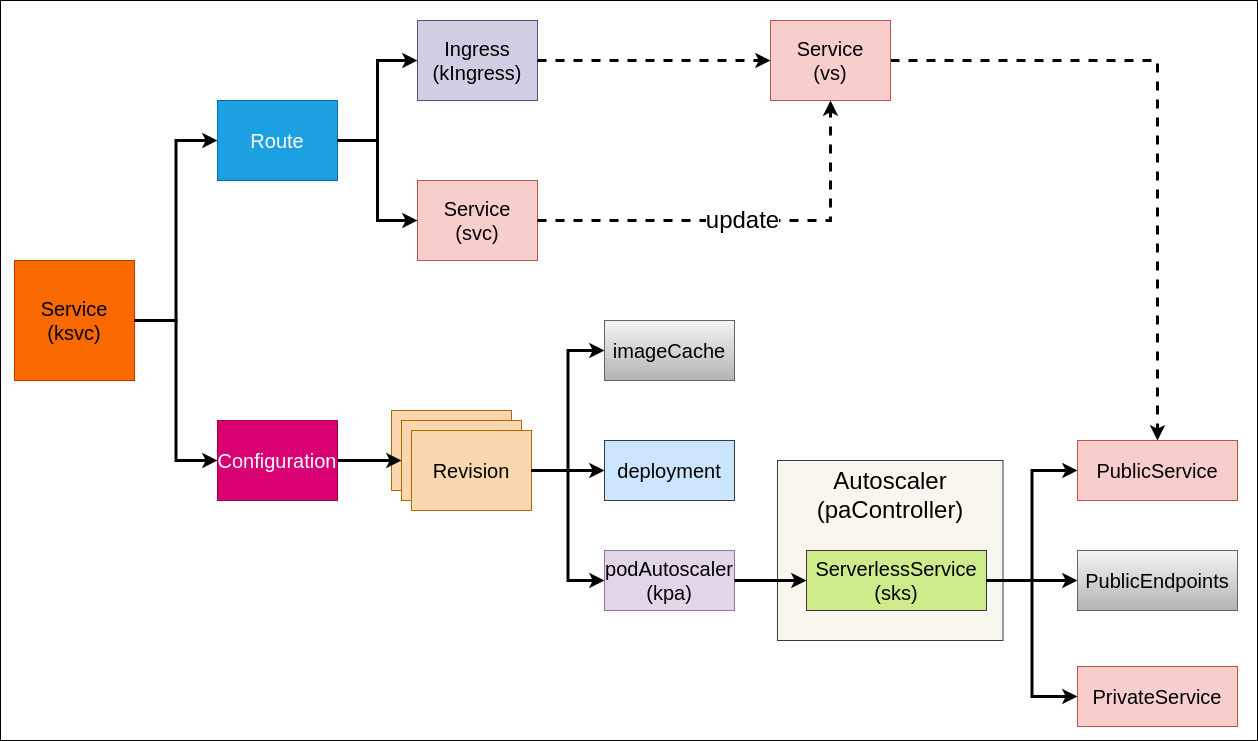
Service 会创建 route、configuration 资源对象。管理 workload 的整个生命周期,在 k8s serving 中其中入口的作用。
Route 会创建 ingress,service 资源对象。其中 ingress 是提供域名供外部访问pa,service 可以理解为 VirtualService 也是一个 k8s service 资源,有两点作用:第一是起着占位作用,防止后续与后续service 冲突,第二是关联 ingress,控制流量和管理流量的作用。
Configuration 会创建 revision 资源,且会管理多个不同的 revision 版本。
Revision 会创建 imageCache、deployment、podAutoscaler 资源对象。
- imageCache 主要是解决冷启动下载镜像慢的问题;
- deployment 是k8s 资源对象,可实现 pod 的滚动升级,revision 通过管理 deployment 来实现扩缩容,刚创建 deployment 时会设定一个初始副本数(可设为0),但是不同版本的revison 对于不同的 deployment;
- podAutoscaler 是 knative中真正控制扩缩容计算的资源对象,如 kpa 会根据并发数进行伸缩对应的 deployment。
podAutoscaler 是真正控制扩缩容的资源对象,它会创建 serverlessService(sks) 资源对象。podAutoscaler 也是通过一个控制器来实现的,其代码主要在 Autoscaler 组件中实现,扩缩容时 Autoscaler 会先根据 metrics 从 queue-proxy 中获取监控指标数据,再通过 decider 计算出扩缩容的期望副本数,然后控制器会将期望的副本数通过
patch 的方式传给pa.Spec.ScaleTargetRef,最后扩缩容的具体流程是通过 ScaleTargetRef(如 deployment)来实现的。podAutoscaler 在knative 中支持两种方式:kpa 和 hpa:- kpa 是基于流量的并发请求数来实现的,优点是:可以实现从 0–>1 或 1–>0 的扩缩容方式,缺点是:只支持 rps 模式的扩缩容方式,knative 默认是使用 kpa 方式。
- hpa 是基于 kubernetes 原生 hpa 方式进行扩缩容,优点是:可以支持 cpu/mem 以及用户自定义的方式进行扩缩容,缺点是:不支持从 0–>1 的扩容,因为当 deployment副本数置为0时流量永远进不来,metrics数据永远为0,这时 hpa 是无法通过 metrics 数据来进行扩缩容的。
ServerlessService(sks) 是对 k8s service 之上的一个抽象,主要是用来控制数据流是直接流向服务 Revision(实例数不为零),还是经过 Activator(实例数为0)。sks 会创建 privateService、publicService、publicEndpoints 资源对象。参考
- privateService 是标准的 k8s service,通过label selector 来筛选对应的deployment产生的Pod,即 svc 对应的 endpoints 由 k8s 自动管控。
- publicService 是不受 k8s 管控的,没有 label selector,不会像 Private service 一样自动生成 endpoints。publicService 对应的 pubilicEndpoints 由 Knative SKS reconciler 来控制的。
注意:sks 工作时有两种模式:proxy和 serve。
- proxy 模式: PublicService 后端 endpoints 指向 Activator 对应的pod地址,所有流量都会流经 Activators 处理后再转发到Revision 后端对应的 pod。
- serve 模式: PublicService 后端 endpoints 跟 Private service一样, 所有流量都会直接指向 Revision 后端对应的 pod。
4. knative serving 组件
knative 部署完成后可以在 knative-serving namespace 下看到创建出的组件:
1 | |
serving 共有 6个主要的组件,其中 5个在 knative-serving 这个 namespace 下面,分别为 activator、autoscaler、autoscaler-hpa、controller、webhook 这五个组件;还有一个 queue,运行在每个应用的 pod里,作为 pod 的 sidecar 存在。
1. Activator:
Activator 主要目的是缓存请求和上报请求指标给Autoscaler,主要功能是在冷启动(从零启动)中缓存请求、突发流量过程中对请求进行负载均衡。
knative 冷启动(从零启动)过程:当对某个 Revision 实例从 0->1 进行冷启动时,流量请求会先经过 Activator 而不是直接到 Revision 的 Pod实例,即当流量从 Ingress 到达 Activator 后会先缓存这些请求,同时 activator 会携带请求指标(请求并发数)去触发 Autoscaler 扩容实例,当 Revision 中的实例 ready 后,Activator 才会将它缓存的请求转发到新的实例中。同时 sks 的模式也从 proxy 模式变为 server 模式。
缓存突发流量过程:为了避免已存在 Pod 的流量过载,Activator 还会充当一个负载均衡器的作用。系统会根据不同的情况来决定是否让 Activator 缓冲并转发请求,当一个应用下中有足够多的 Pod实例时,Activator 将不再转发请求,sks 会被置为 serve状态,请求会直接路由到 Revision 中的 pod 中,从而降低转发带来的网络性能开销。但如果应用下的 pod 数量不够时,activator 会根据请求量来决定将流量转发到哪个实例中,且在不超过设置的负载并发量的前提下,activator 会尽量将所有请求平均分发到后端所有Pod上。
注意:上报指标时,Activator 通过 websocket长连接方式实时上报指标给 Autoscaler,这样能在一定程度上缩短冷启动的时间。而在正常的扩缩容场景中 queue-proxy 与 Autoscaler 之间的数据流通方式是,Autoscaler的 metrics 会自动发现应用的Pod,然后到会主动通过 queue-proxy 指定的端口拉取指标。
2. Autoscaler:
Autoscaler 主要负责收集来自 Activator/queue-proxy 中的指标数据,然后通过其中的 Kpa 模块进行实时的扩缩容操作。其逻辑上由 metrics Collector、decider、pa 三部分组成:
- metrics Collector: 主要是从 queue-proxy 中收集每个实例的指标,然后对指标数据进行聚合。为了实现扩缩容,Collector会搜集所有应用实例的样本,并将收d到的样本反映到整个集群。
- decider:从 metrics Collector 中获取聚合后的指标数据,并通过一定的约束算法计算出扩缩容期望的副本数,之后将该副本数推荐给 pa。简单的计算公式如下:期望的实例个数 = 系统所需的并发数/每个实例的并发数
- kpa(PodAutoscaler): kpa 本身是通过 controller 的方式来实现/维护扩缩容操作的,kpa 会从 decider 中拿到期望的副本数,然后通过 patch 的方式对 deployment 进行更新,实现扩缩容操作。注意 kpa 只支持 rps 方式扩缩容,不支持 cpu/mem 方式扩缩容。
另外,扩缩的实例个数也会受到 Revision 中最大最小实例数的限制。同时 Autoscaler 还会计算当前系统中剩余多少突发请求容量(可扩缩容多少实例)从而决定Activator 是否需要代理转发请求。
3. Autoscaler-hpa:
通过 k8s 原生的 hpa 方式进行扩缩容,支持 cpu/mem 以及用户自定义指标的方式进行扩缩容,但是只支持从 1–>N 的扩容,不支持从 0–>1 的方式进行扩容。
4. Controller: 负责对 Service 整个生命周期的管理,通过 informer 机制和控制器模式对 Service、Route、Configuration、Revision、SKS等资源对象进行 CURD 操作,并不断调协使其达到期望状态。
5. Webhook:
主要负责对创建和更新的参数进行校验。
6. Queue:
负载拦截转发给 Pod 的请求,统计 Pod 的请求并发量,并将请求并发量等指标上报给 autoscaler 对应用进行扩缩容。queue-proxy 是一个伴随着用户容器运行的 Sidecar 容器,跟用户容器部署在同一个 Pod 中。发送到应用程序实例的每个请求都首先通queue-proxy。
queue-proxy 的主要作用是统计和控制到达业务容器的请求并发量,当对一个 Revision 设置了并发量之后(比如设置了5),queue-proxy 会确保同一时间不会有超过5个请求打到业务容器。当有超过5个请求到来时,queue-proxy会先把请求暂存在自己的队列 queue 里,(这也是为什么名字里有个queue的由来)。queue-proxy 会统计进来的请求量,同时会通过指定端口提供平均并发量和 rps(每秒请求量)给 autoscaler。
此外 queue-proxy 还有其他的一些功能:
- 应用请求数等指标统计
- Pod健康检查(k8s探针)
- 代理转发流量
- 判断Ingress是否ready需要通过访问queue-proxy实现
参考:
- https://blog.csdn.net/zhangoic/article/details/104053421
- https://developer.aliyun.com/article/722412
- https://developer.aliyun.com/article/722193
5. knative serving 扩缩容简介
根据上面的介绍,我们知道 knative 中自定义的各种资源,并简单介绍了knative 中主要组件的一些功能,下面将主要介绍 knative 的扩缩容逻辑,knative Serving 模块的核心原理如下图所示,图中的 Route 可以理解成是 Istio Gateway 的角色。
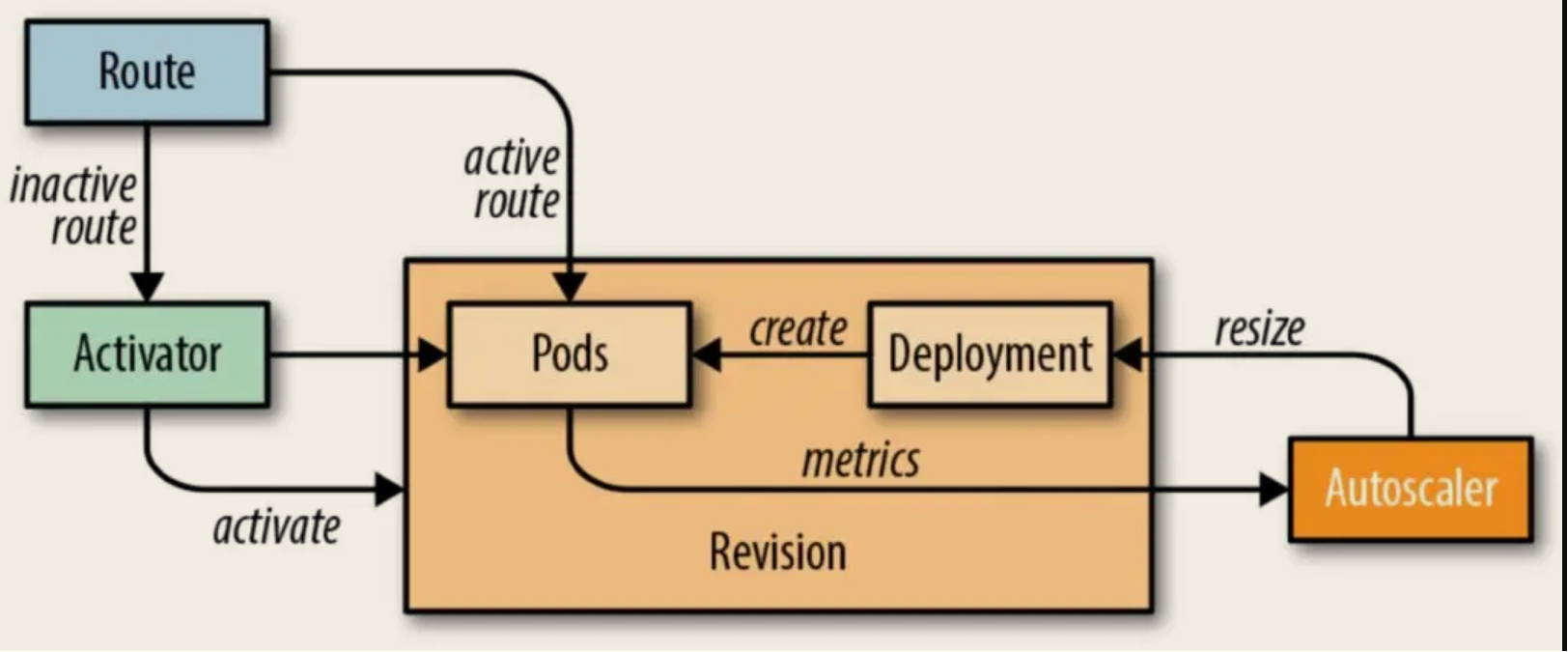
- 当 pod 数为零进来的流量就会指到 Activator 上面;然后 activator 会触发 autoscaler 扩容实例,最后流量才会从 activator 转发到实例上。
- 当 Pod 数不为零时流量就会指到对应的 Pod 上面,此时流量不经过 Activator。knative Serving 会为每个 POD 注入 QUEUE 代理容器 (queue-proxy),该容器负责向 Autoscaler 报告用户容器的并发指标。Autoscaler 接收到这些指标之后,会根据并发请求数及相应的算法,调整 Deployment 的 POD 数量,从而实现自动扩缩容。
更详细的扩缩容逻辑如下所示。
5.1. 冷启动(从零开始扩)
冷启动是指当 revision 下的 pod 数量为 0 时 knative 如何实现从 0–>1 的扩容逻辑,其流程可以用如下图所示:
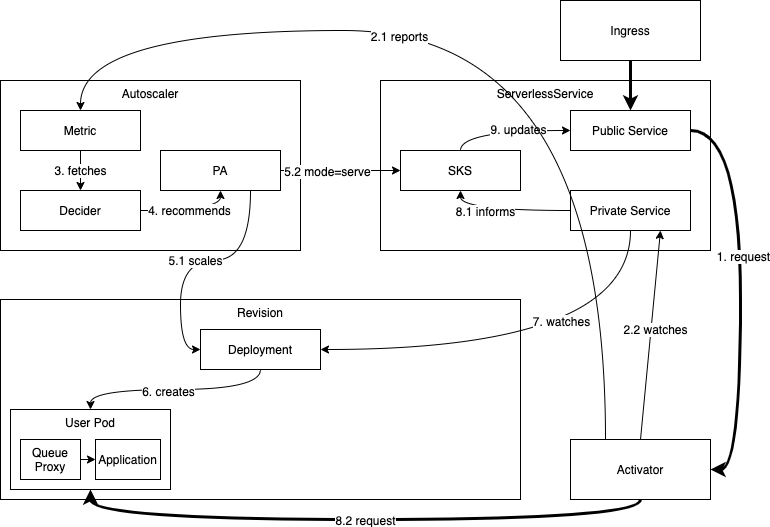
根据上图可知,如果 Revision的实例数为零时,此时系统中有一个请求试图达到该 Revision,为了正常服务系统需要将扩容。流量的处理流程如下所示:
一方面,流量从 ingress 流入,ingress 会将流量转发到 public Service,但由于此时 sks 为 proxy 模式,public Service 中的 endpoints 保存的是 activator 的 ip 地址,所以流量会流入到 activator(1) 中,activator 会缓存流量并计算并发请求数,随后 activator 会触发 autoscaler(2.1) 进行扩容操作,同时不断 watch(2.2) private Service (k8s 原生 service) 中的 endpoints 数据,一但 endpoints 中有 pod 数据(7)(只有健康检查通过的 pod, 能接入流量的 pod 才能加入到 endpoints 中)activator 会将缓存的流量转发给的 pod 实例(8.2)。
另一方面,Autoscaler 收到 Activator 发送的指标后,会立即启动扩容的逻辑,即 metrics 会将抓取到的指标数据交给 decider(3),随后 decider 计算出期望副本数推荐给 kpa(4),kpa 会通过 deployment 来进行扩容(5.1)(6),同时会将 sks 的模式改成 serve 模式(5.2)。这个过程的得出的结论是:至少一个Pod要被创造出来。Deployment创建 Pod 后会更新 Private service 的 endpoint(7), sks 控制器监听到 Private service 的变化后会更新 Public service 并使其与 Private service 的 endpoints 保持一致(8.1)。
综上所述,流量先经过 activator 缓存并触发扩缩容等一系列操作后才将流量转发到健康实例上,最终完成 revision 的冷启动扩容。
5.2. 稳定状态正常扩缩容
稳定扩缩容状态是指 knative 如何实现 m–>n (m 和 n 都不能为 0) 扩缩容,如上图可知其(稳定状态)流程如下:
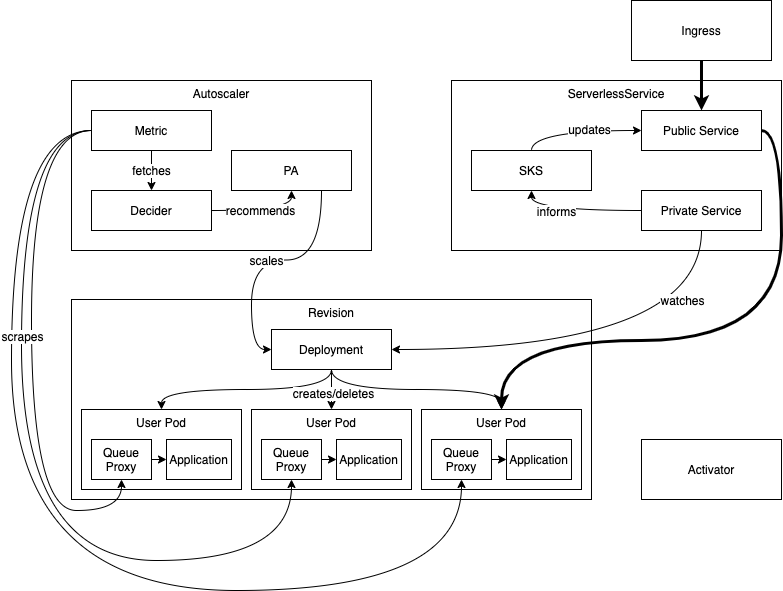
简单过程可理解为:流量从 ingress 流入,经过 public Service 后直接流向了后端实例上。
详细过程如下:
流量通过 ingress 路由到 Public service 后 ,此时 Public service 的 endpoints 对应 Revision 后端中的 pods,即流量可直接到达 endpoints 中。在 knative autoscaler 扩缩容逻辑中,Autoscaler 通过 metrics 不断的从 queue-proxy 暴露的端口中抓取指标,通过 decider 模块计算出副本数的推荐值,最后再通过 pa 来不断的修改 revision 中 deployment 并通过 deployment 来不断调协 Revision 中实例。此外 sks 分模式一直是 serve 模式,并会不断监控 Private service 的状态,保持 Public service 的 endpoints 与 Private service 一致。
5.3. 缩容到零
缩容到零是指 knative 如何实现从 1–>0 的缩容逻辑,其流程如下:
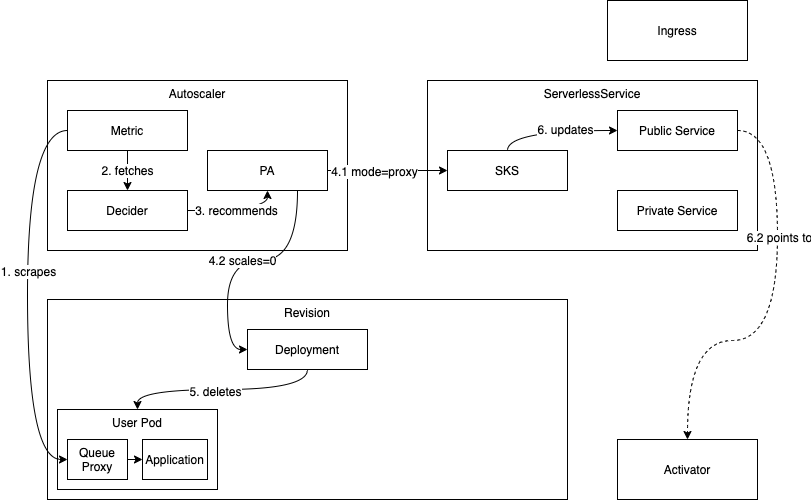
在正常的处理逻辑中,Autoscaler 会不断通过 queue-proxy 获取 Revision 实例的请求指标(1),然后根据这些指标数据来决定扩缩容逻辑。而当系统中某个 Revision 不再接收到请求(此时 Activator 和 queue-proxy 收到的请求数都为 0)(2),autoscaler 通过 metrics 从 queue-proxy 中抓取到的指标数据也为 0,此时 Decider 会将推荐值0 交给 pa (3),随后 pa 会修改 deployment 的副本数为 0(4.2),之后的所容逻辑有 deployment 控制器来控制。而在 knative 需要删掉 Revision 的最后一个Pod之前,会有些特殊处理:
- pa 控制器会将 SKS 变为 proxy 模式(4.1),此时 SKS 的 Public service 后端的 endpoints 变为 Activator 的IP,所有的流量都直接导到 Activator(6.2)中。
- 在删除最后一个 pod 之前会设置一个宽限期(可通过_scale-to-zero-grace-period_进行配置),如果在宽限期内依然没有流量到来,则Revision 的最后一个 pod将被删除(5)。
6. 总结
本文主要讲述了 knative serving 是如何实现的,knative serving 是建立在 k8s 之上的服务,通过 crd 的方式来实现其业务逻辑。本文先是介绍了实现 knative 的技术背景,随后介绍了knative 的工作原理以及 crd 相关资源对象,之后简单介绍了 knative 中几个重要组件,knative 的crd 资源通过这些组件的实现来完成 knative 的扩缩容逻辑。最后详细介绍了 knative 的三个特殊的扩缩容逻辑,冷启动扩容、正常扩缩容、缩容到零,其中零启动扩容方式是 knative 技术的一大亮点,但其也存在诸多缺点,其中最大的确实就是冷启动的时间太长(号称冷启动时间为 6s),这在绝大多数应用场景中是不可忍受的,所以对 knative 的性能优化将是社区和行业亟待解决的一个大问题,其中网易对此有个优化实践.
7. 参考
- https://github.com/knative/serving/tree/release-1.5/
- https://github.com/knative/serving/tree/release-1.5/docs/scaling
- https://zhuanlan.zhihu.com/p/353216880
- https://cloud.tencent.com/developer/news/617053
- https://cloud.tencent.com/developer/news/652064
- https://blog.tianfeiyu.com/source-code-reading-notes/knative/knative_serving.html
- https://blog.csdn.net/zhangoic/article/details/104053421
- https://developer.aliyun.com/article/722412
- https://developer.aliyun.com/article/722193
- https://zhuanlan.zhihu.com/p/172431080